Layanan Proxy

Proxy Perumahan
Lebih dari 200 juta IP yang diizinkan dari ISP nyata. Kelola proxy melalui dashboard.

Proxy Perumahan (Socks5)
Lebih dari 200 juta IP nyata di 190+ lokasi

Paket Proxy Tak Terbatas
Penggunaan IP dan lalu lintas tak terbatas, Proksi Perumahan Rotasi Cerdas AI

Proxy Perumahan Statis
Proxy khusus tahan lama, proxy perumahan tanpa rotasi

Proksi Pusat Data Khusus
Gunakan lebih dari 700 ribu IP datacenter yang stabil dan cepat di seluruh dunia.

Proxy Seluler
Akses lebih dari 10 juta kumpulan IP seluler yang etis dengan 160+ lokasi dan 700+ ASN.





Scraper
Kumpulan data terstruktur publik dari semua situs web
Proxy
Proxy Perumahan
Lebih dari 200 juta IP yang diizinkan dari ISP nyata. Kelola proxy melalui dashboard.
Mulai dari
$0.6/ GB
Proxy Perumahan (Socks5)
Lebih dari 200 juta IP nyata di 190+ lokasi,
Mulai dari
$0.03/ IP
Paket Proxy Tak Terbatas
Penggunaan IP dan lalu lintas tak terbatas, Proksi Perumahan Rotasi Cerdas AI
Mulai dari
$18/ Hour

Memutar Proxy ISP
Memutar Proxy ISP ABCProxy menjamin waktu sesi yang lama.
Mulai dari
$0.4/ GB
Proxy Perumahan Statis
Proxy khusus tahan lama, proxy perumahan tanpa rotasi
Mulai dari
$4.5/MONTH
Proksi Pusat Data Khusus
Gunakan lebih dari 700 ribu IP datacenter yang stabil dan cepat di seluruh dunia.
Mulai dari
$4.5/MONTH
Proxy Seluler
Lebih dari 200 juta IP yang diizinkan dari ISP nyata. Kelola proxy melalui dashboard.
Mulai dari
$1.2/ GB
Scraper

Pembuka Blokir Web
Simulasikan perilaku pengguna nyata untuk mengatasi deteksi anti-bot
Mulai dari
$1.2/GB

Serp API
Dapatkan data mesin pencari real-time dengan API SERP
Mulai dari
$0.3/1K results


Browser Scraping
Browser scraping yang dapat diskalakan dengan fitur pembukaan blokir dan hosting bawaan
Mulai dari
$2.5/GB

Dokumentasi
Semua fitur, parameter, dan detail integrasi, dilengkapi dengan contoh kode dalam berbagai bahasa pemrograman.
Alat
Sumber Daya
Addons

Ekstensi ABCProxy untuk Chrome
Ekstensi pengelola proxy Chrome gratis yang bekerja dengan penyedia proxy apa pun.

Ekstensi ABCProxy untuk Firefox
Ekstensi pengelola proxy Firefox gratis yang bekerja dengan penyedia proxy apa pun.

Pengelola Proxy
Kelola semua proxy menggunakan antarmuka APM yang dikembangkan sendiri oleh ABCProxy.

Pemeriksa Proxy
Pemeriksa proxy online gratis untuk menganalisis kesehatan, jenis, dan negara.
Proxy

Pengembangan AI
Dapatkan data web multimodal skala besar untuk pembelajaran mesin

Penjualan & E-niaga
Kumpulkan data harga setiap produk di seluruh web untuk mendapatkan dan mempertahankan keunggulan kompetitif

Intelijen Ancaman
Dapatkan data real-time dan akses berbagai lokasi geografis di seluruh dunia.

Pemantauan Pelanggaran Hak Cipta
Temukan dan kumpulkan semua bukti untuk menghentikan pelanggaran hak cipta.

Media Sosial untuk Pemasaran
Kuasai ruang industri Anda di media sosial dengan kampanye yang lebih cerdas, antisipasi tren besar berikutnya

Agregasi Harga Perjalanan
Dapatkan data real-time dan akses berbagai lokasi geografis di seluruh dunia.
Berdasarkan Kasus Penggunaan

English

繁體中文

Русский

Indonesia

Português

Español

بالعربية
Proxy






Scraper
-

Serp API
-

Pengunduh Video
-

Browser Scraping
-

Pembuka Blokir Web
-

AbcCopilot
-
YouTube
-
Google
-
Bing
-
Yahoo
-
Walmart
-
DuckDuckGo
-
eBay
-
Yelp
-
Amazon
-
Twitter
-
Ad Tech
-
eCommerce
Harga



Pengembang
-
Dokumentasi
-
Proxy
-
Pembuka Blokir Web
-
Serp API
-
Scraper API Playground
Tetap Update -
Blog
-
FAQ
-
Kemitraan Akademik
-
Program Mitra
-
Program Afiliasi
-
Tutorial Video
-
Lokasi
-
Ekstensi ABCProxy untuk Chrome
-
Ekstensi ABCProxy untuk Firefox
-
Manajer Proxy
-
Pemeriksa Proxy
Solusi
Indonesia
- English
- 繁體中文
- Русский
- Indonesia
- Português
- Español
- بالعربية


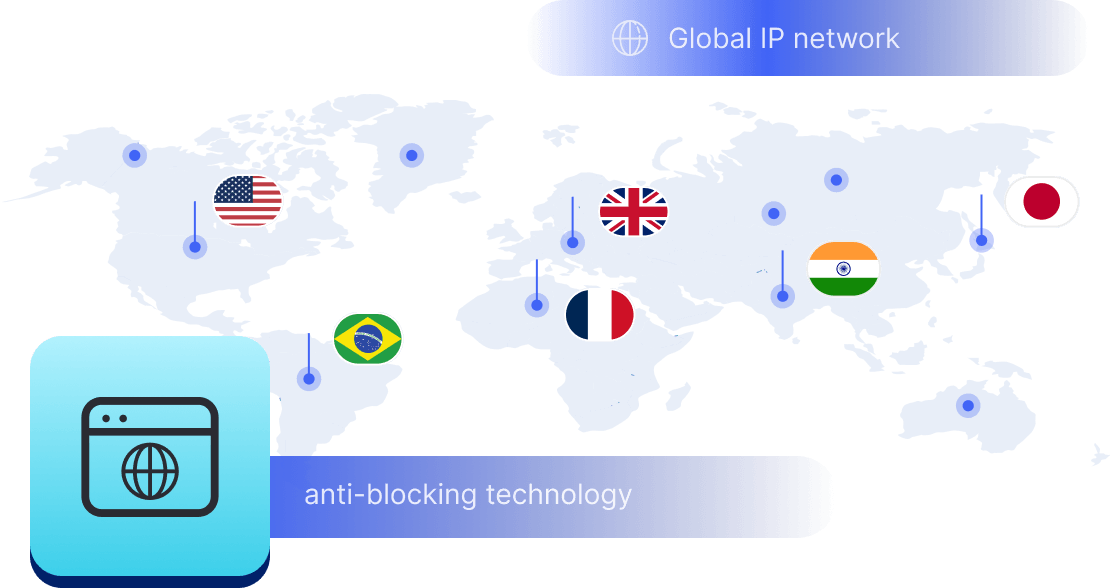


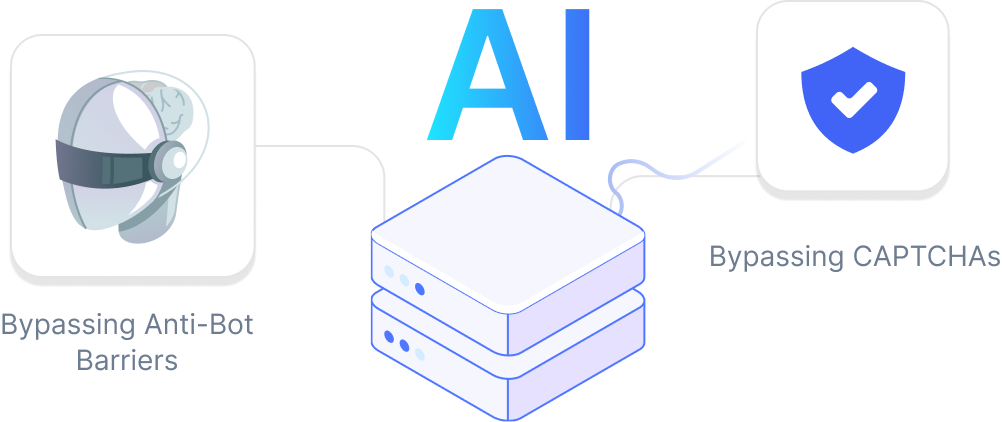












 Rollover Lalu Lintas
Rollover Lalu Lintas